
Lisa
General thoughts and specific hacks from the domains of science, cognition and programming
The time has come, where I really need to just sit down and write my thesis. So obviously I spent about a week preparing my LaTeX template before I realized not a single actual word had been written. In the meanwhile everyone I meet asks me the same question: “so, how’s the thesis going?” Actually this question is still leagues better than the inevitable follow-up “And what are you going to do after?”
Anyway, think of the time I could save if I could just shove a chart of my progress in people’s faces. “why don’t you just see for yourself?”
The result is this:
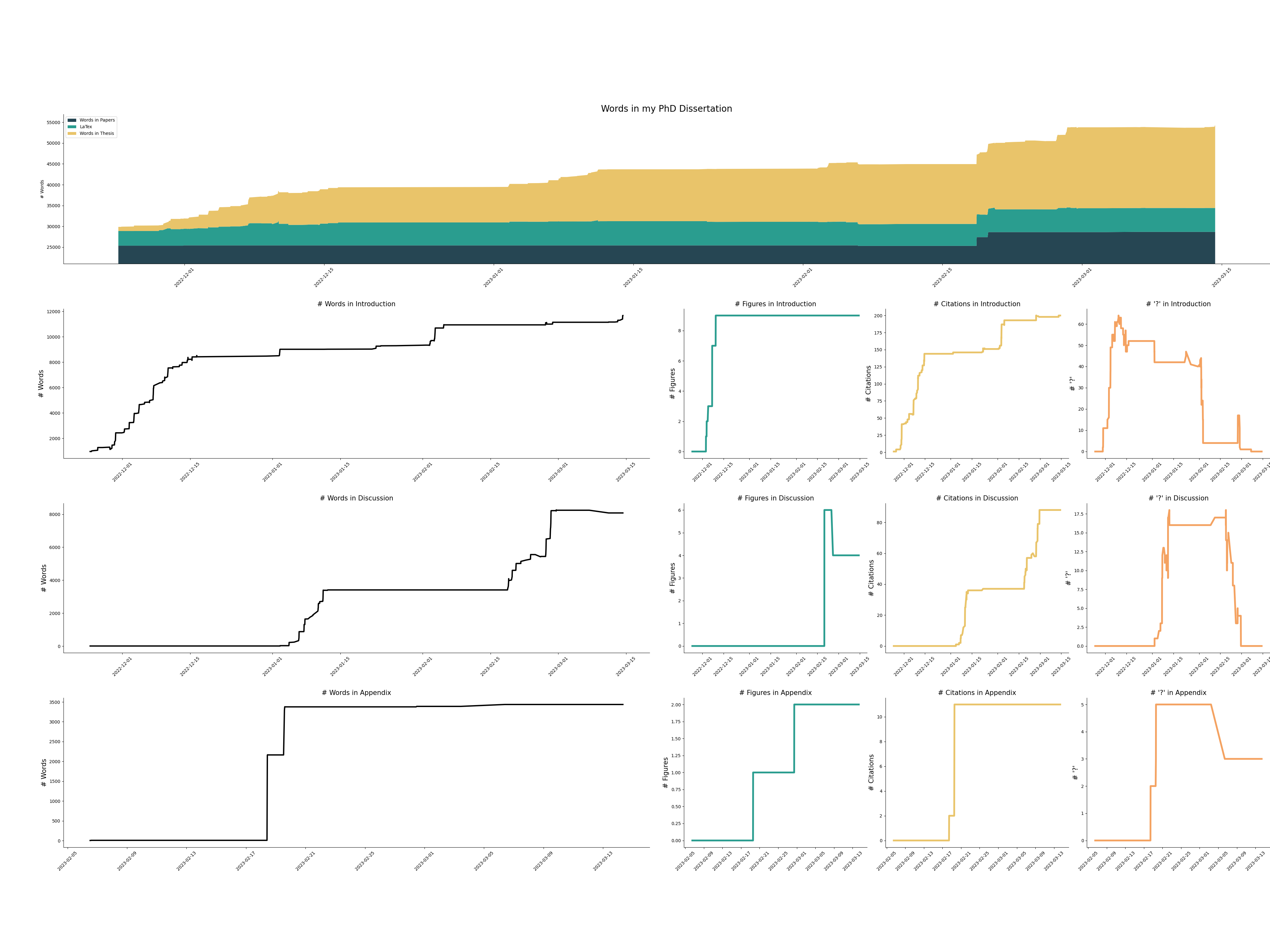
If anyone wants to reproduce this wonder for their own writings, and save their valuable procrastination time for something else, here’s how it’s done.
I use Overleaf for writing the actual text. Overleaf has the option of interacting vis a git repo that they host. In the course of setting this up I figured out that they don’t actually use it in the background- instead Overleaf just creates a commit in the moment where you request it. You can find the link for the project if you click the little Git button in the menu, and it will give you a link like https://git.overleaf.com/your_project_number which you can clone from and push to. Its neat!
So now, since commits to that repo are only generated the moment you pull, you’re going to need to pull regularly to track the progress. I use MacOS, where there’s a system of setting up deamons to perform little automations like this called launchd. I mainly looked at this tutorial to set it up. Basically you need to make a plist file with some identifying name like de.lisa.overleaftracking.plist in the directory ~/Library/LaunchAgents/. That file has the following contents:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string> de.lisa.overleaftracking.plist</string>
<key>RunAtLoad</key>
<true/>
<key>StartInterval</key>
<integer>1800</integer>
<key>StandardErrorPath</key>
<string>/YOUR/PATH/HERE/stderr.log</string>
<key>StandardOutPath</key>
<string>/YOUR/PATH/HERE/stdout.log</string>
<key>EnvironmentVariables</key>
<dict>
<key>PATH</key>
<string><![CDATA[/usr/local/bin:/usr/local/sbin:/usr/bin:/bin:/usr/sbin:/sbin]]></string>
</dict>
<key>WorkingDirectory</key>
<string>/YOUR/PATH/HERE</string>
<key>ProgramArguments</key>
<array>
<string>/bin/bash</string>
<string>collect_overleaf.sh</string>
</array>
</dict>
</plist>
Thats mostly boilerplate stuff, except adding your own directories in the right places. I decided to just make the working directory a directory that included the git folder I wanted to pull from. Then in the working directory I put the bash script that I want to execute, i.e. collect_overleaf.sh. Lastly, you’ll want to add the interval at which it runs the script. here I put it to 1800s which means every 30 minutes.
Then, I added the collect_overleaf.sh script to the working directory. It could be as simple as
#! /bin/bash
cd XXX
git pull
but in the end I made it update a table of counts every time it pulls with a count_words_now.sh script and then generate a plot with makeplot.py (Next section shows off those!), so it looks like this:
#! /bin/bash
date
cd XXX
a=`git pull`
if [ "$a" = "Already up to date." ]; then
echo nochange
elif ["$a" = "fatal: unable to access 'https://git.overleaf.com/XXX/': Could not resolve host: git.overleaf.com" ]; then
echo fatal
else
sleep 5
bash count_words_now.sh
source /PATH/TO/MY/virtual_env/bin/activate
cd ..
python makeplot.py
echo madeplot
fi
Don’t forget to chmod -x collect_overleaf.sh to make it executable! Then you can start the deamon:
launchctl list shows all running launchctl jobslaunchctl load ~/Library/LaunchAgents/de.lisa.overleaftracking.plist adds the jobunload removes the jobAt this point I should note that I had some trouble with the deamon not runnig, that ended up being caused by missing permissions for accessing the file system for some reason. I won’t get into that terribly boring side quest, and cross my fingers that you run into different problems.
So now I have the git repo, with all the commits. I thought it would be easy to use gitpython to just get the differences between commits to find number of words changed and other such metrics. It was not easy! Number of lines changed was easily accessible that way, but to get words, it would have been necessary to parse a bunch of git trees… nah!
Instead I wrote a bash script that uses TeXcount. TeXcount is neat because it separately outputs counts for words in the text and all the LaTeX commands. So, this is the previously mentioned count_words_now.sh script:
commit=`git rev-list --all | head -1`
for file in `git ls-tree -r --name-only $commit`; do
#echo $file
com=`git log -n 1 --pretty=%ad $commit`
words=`git archive $commit $file | tar -x -O | wc -w`
lines=`git archive $commit $file | tar -x -O | wc -l`
figs=`git archive $commit $file | tar -x -O | grep -o -i "\\\includegraphics" | wc -l`
cites=`git archive $commit $file | tar -x -O | grep -o -i "\\\cite" | wc -l`
qs=`git archive $commit $file | tar -x -O | grep -o -i "\?" | wc -l`
output='0,0,0,0,0,0,0'
if [ ${file:(-3)} == "tex" ]; then
output=`/Library/TeX/texbin/TeXcount $file -nosub -template={1},{2},{3},{4},{5},{6},{7} | sed "s/[^0-9,]*//g" | grep '\S'`
fi
echo $com, $file, $words, $lines, $figs, $cites, $qs, $output >> table.csv
done
Basically it iterates over the files, and then counts words and lines first with wc and then with TeXcount. I ended up using mainly the TeXcount counts, but kept the others, because why not.
Why does the TeXcount command look like such a mess, you might ask?
`/Library/TeX/texbin/TeXcount $file -nosub -template={1},{2},{3},{4},{5},{6},{7} | sed "s/[^0-9,]*//g" | grep '\S'`
Well!
-nosum omits the subcounts-template argument is really convenient to getting the counts as a nice table.TeXcount gives an error. So the sed and grep commands filter out the numbers I need. There is probably a neater way of doing the same thing, but my bash and regex-fu is not super strong, and this works.Lastly, the fun part! The table.csv can just be loaded in pandas using read_csv. If you don’t want to make your own pretty plots, here’s the code: