
Lisa
General thoughts and specific hacks from the domains of science, cognition and programming
This is just a quick update on how things have developed in 2019. Unfortunately some of the things outlined in the previous post I wrote on the subject have since been changed. ReMarkable changed their file format, which broke all the cairo code I’d written. Its probably not unsalvageable but I haven’t has the time to fix it. Someone else fixed the rm2svg script though, so that gives me something to work with. My version of the conversion scripts still live in my maxio fork, and thats where I will be pushing my updates.
On the remarkable each File (pdf or notebook) now exists as a folder named by a hash. Inside this folder we have a *.rm file for each page in the file, numbered by page number. The rm2svg code converts the the markings inside an individual *.rm file to an svg.
The idea stays largely the same:
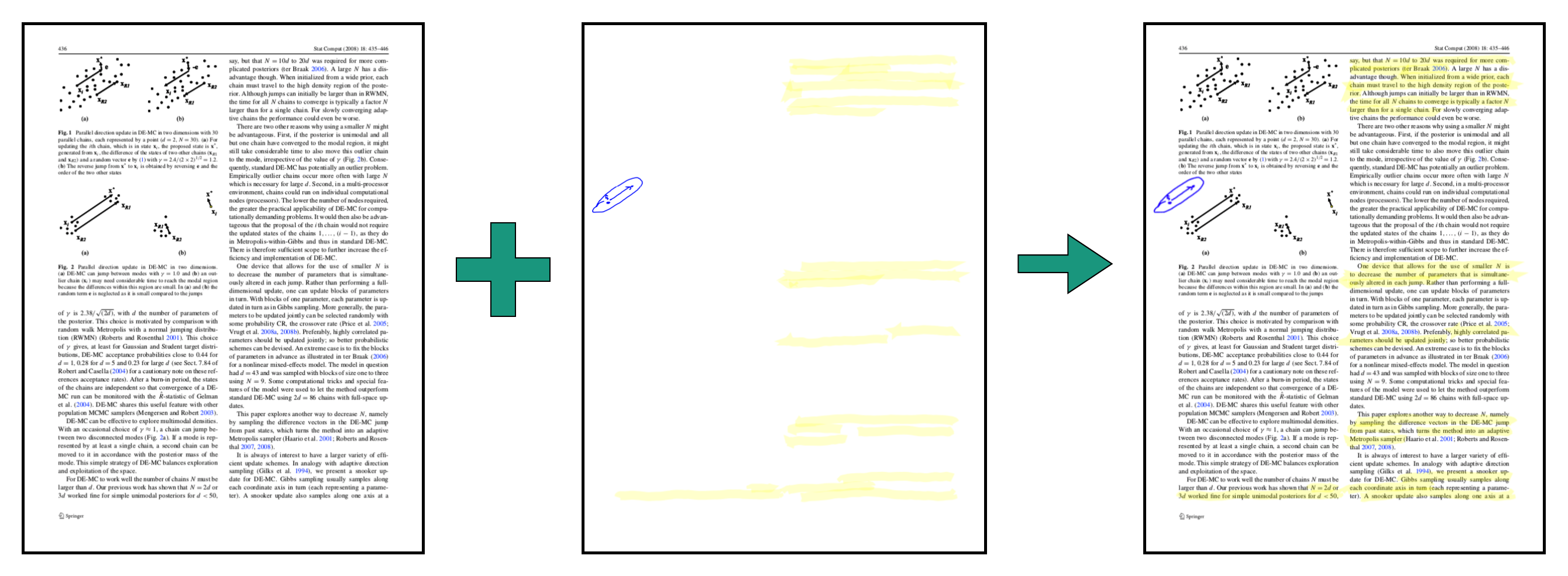
rsvg-convert -f pdf -o name.pdf name.svg)pdftk input.pdf multistamp annot.pdf output final.pdf)I made a python notebook that illustrates this and it’s implemented in the ConvertAnnotatedPdf function of my sync script.
For notebooks the steps are basically the same as for pdfs, only that depending on the usecase you would stop at step 3.
If you want your notes to keep the backgrounds though, you can just use the same procedure, only that the original PDF is now the background template.
Those are hidden on the reMarkable under /usr/share/remarkable/templates. A nice additional benefit of knowing that is that you can add your own templates!
My implementation is here.
Well, the sync script which I have now referenced a couple of times is basically a little commandline utility which I use to interact with the rM. I am actually remarkably (cough) happy with it and throughout all the updates it’s kept chugging along with only minor changes. It can do 3 things:
This makes them easier to work with. The obvious drawback of copying everything over every time is that it takes a while. While I’d like a Rsync-like solution that only copies changed files, I think all in all, as long as the number of files I have on there doesn’t explode, it will be fine.
Uses the local File backup to convert all *.rm files to pdfs and sorts them into my folders. The converting itself I have talked about: if the file has changed compared to the last version I exported, I run the procedure above. The script is currently set up to sort into a papers, books, and notes, as this makes sense for my usecase. But it should be fairly easy to adjust to whichever structure other people have.
Compares the existing files in my local ReMarkable Backup folder (as a proxy for what is on the rM right now) to the files in my local Reference folder (the folder of which the contents are mirrored on the reMarkable) and uploads all that are not yet on the rM. I am still doing the upload to the main front page folder of the reMarkable to sort them by hand, because as long as there are no file tags in the reMarkable system, I need to make sure I can actually find the new files I’ve recently uploaded for reading. I did get the repush script to work at some point and that should solve the problem for anyone who wants to push to folders directly.
thats all the updates for how that project is going. I’d be interested in hearing how the official syncing and converting apps have developed. From what I’ve seen there have been a few changes which have probably made the official solution more usable.